4 min to read
Data Management in Fog Computing
Understand data management in fog computing
ReadMe
아래 내용은 Rajkumar Buyya, Satish Narayana Srirama 저서인 For and Edge Computing: Principles and Paradigms 책의 내용을 주로 다루고 있습니다.
Motivation
포그 컴퓨팅은 IoT에 대한 거대하고 실시간으로 이뤄지는 데이터 관리 시스템에 대한 중요한 역할을 하고 있습니다. 센서와 디바이스들은 주기적으로 데이터들을 생성하지만 그 데이터에는 불필요하고 노이즈이거나 반복적인 데이터들이 존재합니다. 그럼에도 불구하고 에러, 패킷로스, 데이터 밀집에서 생기는 누락 등을 알기위해 데이터 전송을 해야합니다. 그러다보니 각 IoT 디바이스에서 생기는 데이터 누락과 자원의 제약의 이유로 프로세싱과 생성된 데이터의 저장들에 캐파가 부족한 실정입니다.
포그 컴퓨팅 패러다임에서 엔드 디바이스에 가깝게 저장(Storing), 처리(Preocessing), 네트워크(Network)를 가져오는 것에 적절한 솔루션을 고려해야 합니다. 포그 컴퓨팅은 암호화와 암호 해독, 데이터 융합, 종속성, 로드밸런싱을 제공하면서 온-사이트 처리와 저장(on-site processing and storage)을 좀 더 프라버시하게 활성화합니다.
Advantages of data management in for computing
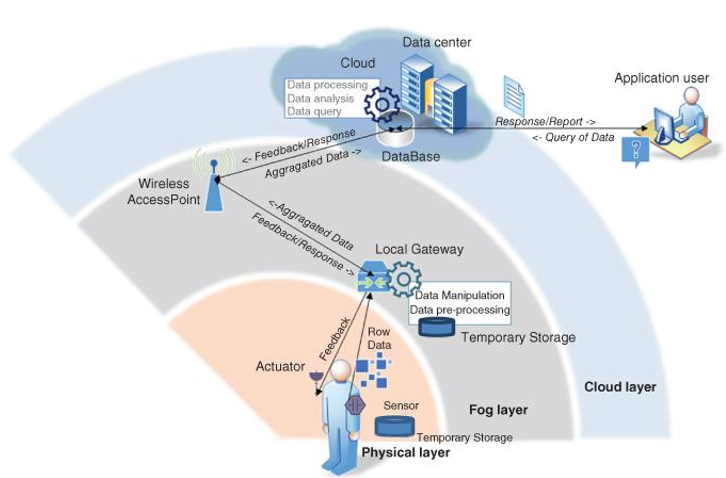
포그는 디바이스와 클라우드 단 사이에 존재하는 중개자 역할이고 임시데이터 저장(temporary data storage), 예견된 처리(preliminary processing) 그리고 데이터 해석(analytics)을 담당하고 있습니다.
데이터 관리, 처리, 가상화, 그리고 서비스 프로비져닝은 모두 포그 레이어에서 끝납니다. 예를들면 Foglet은 포그 서버들과 포그 엣지단 사이에 인터페이스하면서 미들웨어의 역할인 소프트웨어 에이전트입니다. 이것은 또한 모니터링, 제어, 유지보수로 사용됩니다. 포그 데이터 관리는 데이터 핸들링과 연관이 있습니다. 예를 들면 데이터 집합 방법론, 데이터 필터링 기술, 데이터 배치, 데이터 보안성 제공(data agreegation approaches, data filtering techniques, data placement, providing data privacy)이 있죠. 좀 더 명확하게 나눠보겠습니다.
- 향상된 효과성: 포그 레이어에서 데이터에서의 지역적 처리와 결측치 제거, 반복성, 혹은 필요없는 데이터는 네트워크 부하를 줄여주고와 증가된 네트워크 효과를 봅니다.
- 보안레벨의 증가: 엣지 디바이스와 클라우드 사이의 데이터를 전송할때 어떤 관리도 없고 제공되는 정보를 암호화하여 처리합니다.
- 향상된 데이터 품질: 앞에서 말한 데이터 처리와 필터링을 통하여 데이터 품질이 올라갑니다.
- 양 끝단 지연 감소: 포그레이어의 역할로서 지연이 감소됩니다.
- 의존성 증가: 시스템 종속성은 예상된 서비스를 제공하기 위함입니다. 포그 디바이스와 로컬 네트워크는 클라우드 네트워크와 로컬 프로세싱에서 생길만한 가능한 문제를 다룰 수 있습니다.
- 비용 감소: 포그레이어에서 지역적인 데이터 처리와 데이터 압축은 네트워크 사용 비용과 클라우드 처리, 저장 비용을 낮춥니다.
Fog Data Life Cycle
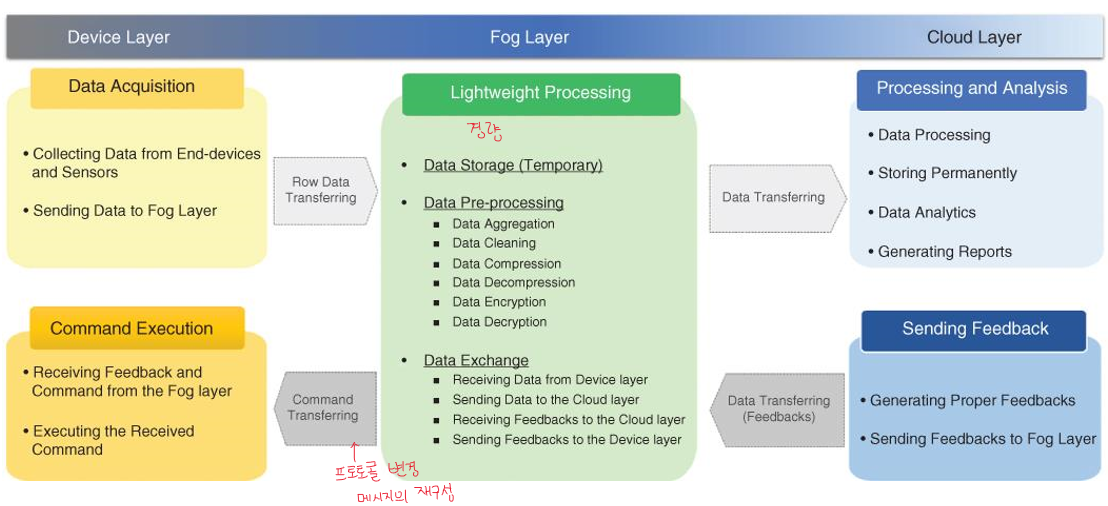
포그 데이터의 라이프 사이클은 1) Data Acquisition 2) Lightweight Processing 3) Processing and Analysis 4) Sending Feedback 5) Command Execution 으로 나뉩니다. 엣지 컴퓨팅은 포그, 클라우드도 중요하지만 데이터 들의 특성들때문에 더 높은 기술로 인정받고 있는 만큼 데이터 특징들도 같이 나열하겠습니다.
Data Characteristics
- Heterogeneity: 회사별, 디바이스 타입별로 다른 포맷과 프로토콜을 지니고 있습니다.
- Inaccuracy: 센싱된 값이 정확하지 않을 수 있습니다.
- Weak semantics: 위의 두 특성(이종성, 불확실성)으로 인하여 데이터 구조나, 데이터 소스만 보면 수식적으로 명확하게 정의하기 어렵습니다. 그리고 데이터 자체가 수식적으로 접근하면 이해하기 어려운 값이 나올 수도 있습니다.
- Velocity: 디바이스에 따라 데이터 취득 주기가 다릅니다. 초 단위 분 단위 하루 단위일 수도 있습니다.
- Redundancy: 동일한 내용을 의미하는 데이터가 반복되거나 아니면 다른 디바이스에 존재할 수 있습니다.
- Scalability: 많은 수의 디바이스를 데이터 샘플 주기로 나눌때마다 다른 시나리오가 나올 수 있습니다.
- Inconsistency: 불확실성과 중복성으로 인하여 처리를 하고 난 다음 취합한 데이터가 원 데이터와 다를 수 있습니다.
그래서 이를 처리하는 데에 사용하는 전처리 기법들을 아래의 용어로 부릅니다. 아주 처음에 얘기했던 CIOT 도전과제의 BLURS를 지키기 위함이 있습니다. (Bandwidth, Latency, Uninterrupted, Resource-constraint, Security)
- Data cleaning: 하나의 필터링 기법이며 데이터를 가공하거나 결측치를 보간하고 노이즈 값에 대한 스무딩 기법을 의미합니다. 여기에는 1) Declarative data cleaning, 2) Model-based data cleaning이 있습니다.
- Data Fusion: aggregation method입니다. 상관성을 보고 직교하는 피쳐를 추출하는 것도 포함되며 말 그대로 붙이고, 예측하는 것도 있습니다.
- Edge Mining: 엣지 디바이스를 응용하는 것으로 전송 데이터에 대해 에너지 효율 측면으로 개선하는 기술을 의미합니다.
- Data Privay: 데이터 개런티를 보장하는 기술쪽으로 있습니다.
- Data Storage and Data Placement: 너무 가까우 붙여도 안됩니다. Edge device의 모바일리티 때문에 Data placement와 Data storage는 제일 적당한 위치에 놓아져야 합니다.
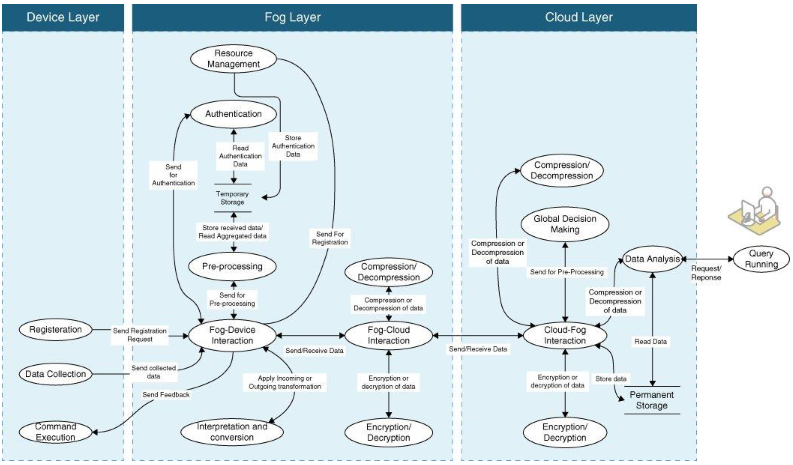
Layers that Focused on Data Management
Device Layer
디바이스 레이어의 모듈들은 모듈 전환(기능 전환), 데이터 수집 모듈 그리고 커맨드 실행 모듈이 있습니다.
-
Registration
물리적 디바이스들은 네트워크라는 의미로 합쳐질 수 있습니다. 마찬가지로 네트워크에서 상황에 따라 빠져나올 수 있습니다. 동적으로 동작하기 때문에 전환을 의미하며 메시지를 전송하고 받는데 있어서 필수적인 요소입니다. 디바이스들은 유일한 ID나 키 값을 가지고 메시지에 붙으며 동작하는데 이는 FEC의 장점 SCALE(Security, Cognition, Agility, Latency, Efficiency)에서 보안, 즉 권한 처리를 위해 동작합니다.
-
Data Collection / Command Execution
등록된 센서들을 수집하고 전송하는 것에 있어서 포그레이어의 역할이 중요합니다. 액츄에이터는 이 모듈에서 포그레이어로 커맨드를 주고 받습니다.
Fog Layer
- Resource Management: 저번에 얘기했던 Resource 도전과제에 대해 가장 중요한 것은 탈중앙화였습니다. 이에 대한 내용은 전 포스팅에 있고, Temporary Storage, Authentication이 있습니다.
- Interpretation and Conversion: 데이터는 전송은 다양한 기술을 이용하여 전송됩니다. 기술보다는 프로토콜에 가까운데, Wi-Fi, Bluethooth, ZigBee, RFID 등이 있습니다.
- 포그 레이어 단에서는 흔히 아는 방법들인 전처리 기법도 포함됩니다.
- Encryption / Decryption: Privacy and Protect를 위하여 메시지에 처리작업을 거칩니다.
- Compression/Decompression: 전송 효율을 위해서 압축과 비압축 알고리즘도 포함됩니다.
Cloud Layer
- Permanent Storage: 다른 포그 존으로부터 데이터를 받고 영구적인 저장소에 보관합니다. 포그까지는 임시적인 스토리지를 썼는데 클라우드에 최종적인 전송을 위해서죠.
- Global Decision-Making: Fog까지는 Latency를 위해서 서비스를 붙여 빠른 의사결정을 했으나, 전 데이터들을 가지고 분석하는 Cloud layer에서는 전역에 통하는 Global decision making을 할 수 있습니다. 당연히 무거운 딥러닝 모델도 탑재할 수 있죠.
- Encryption/Decryption, Compression/Decompression: 저장소의 효율을 위하여 그리고 엣지컴퓨팅의 보안성을 지키기 위하여 클라우드 레이어 단에서도 데이터 처리를 합니다.
- Data Analysis: 빅데이터 처리가 이에 해당됩니다.
Comments